今天公事繁忙,Skylar 沒有出門買午餐的餘裕,決定使用 Uber 訂購外送。App 顯示的預估抵達時間為 40 分鐘後,他盤算著剛好下一場會議結束後,剛好就能吃到午餐。
Uber 是怎麼預估外送時間的呢?同時要考量媒合外送員、等候商家備餐,和外送員的路途時間。同一條路線也會因為時間、天氣和交通狀況而有所變化。並不能單純考慮路線本身,也無法直接使用歷史數據。
為了考慮到所有資料特徵,做出最精準的判斷,Uber 提出 DeeprETA 這個模型架構,這是一個混合傳統估計路線的方式、和新的機器學習技術之架構。
DeeprETA 的介紹會分為兩個部分:
好的,在正式進入 Uber 的預估時間模型之前,我們今天先來聊聊什麼是 self-attention 吧!
一般比較基本的模型,如分類器或迴歸模型,都是輸入一個向量,再輸出一個類別或一個數值。但是,現在機器學習應用的場景五花八門,如果想要輸入一篇文章、一段音樂,或是一句話,輸入的會是一整組向量,甚至這些向量的長度都不一。另外,這些向量之間彼此是有一定關聯的,模型是否能夠同時考慮所有內容呢?
這就是 self-attention 想要解決的問題,不僅能夠輸入一整組長度不一的向量,也能夠同時考慮所有向量資訊。
Self-attention 模型會接受一個序列的輸入,如 [a1, a2, a3, a4],並輸出 [b1, b2, b3, b4]。其計算過程可以拆解成以下幾個步驟,我們以第一個序列 a1 為示範。
Self-attention 的基本概念是利用向量內積,在整個序列中找出和 a1 最相似的元素。方法是計算每個元素(a1-a4)的 key,再和 a1 算出來的 query 做內積,得到 attention scores α',再利用這個 α' 加權各元素計算而得的 value,最後得到 b1 當作 output。
讓我們詳細來看每個步驟。
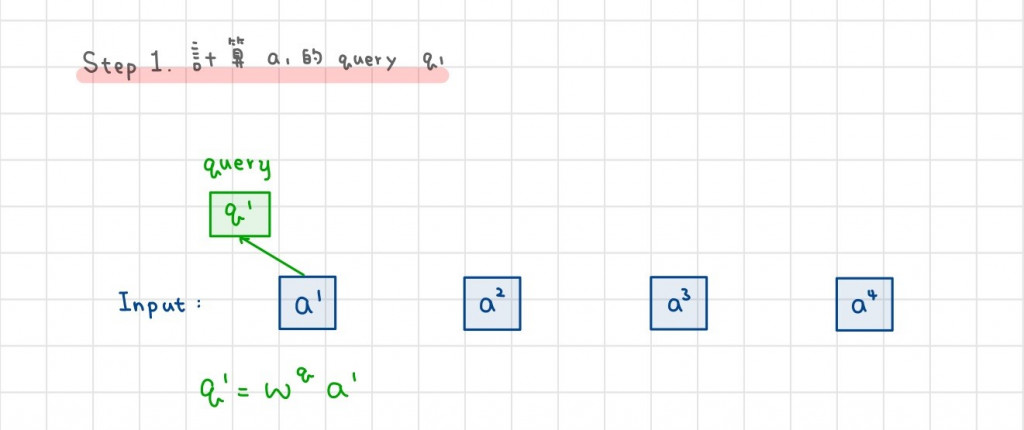
首先,輸入的 a1 會先轉成 query q1 以供後續使用,只要將 a1 乘以矩陣 Wq 即可。
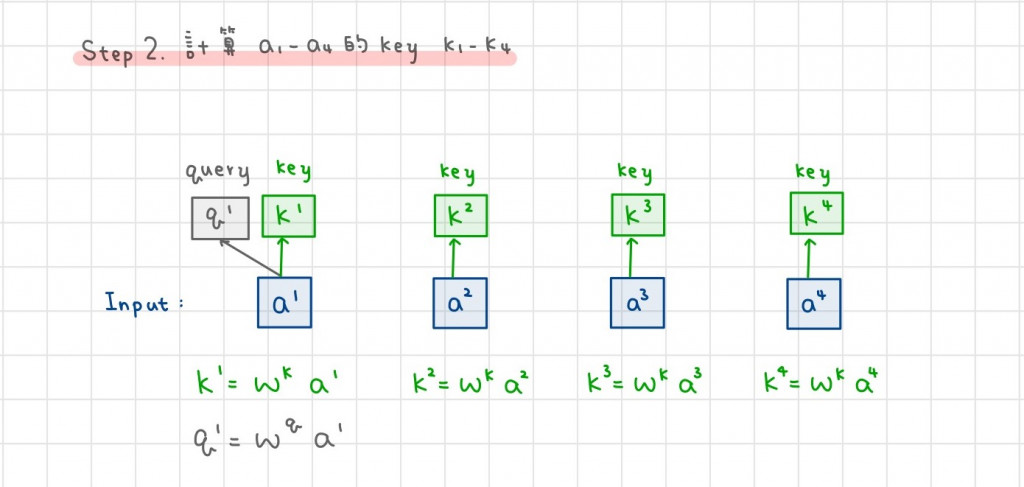
所有的 a 都乘上一個矩陣 Wk,得到每個 a 各自的 key k。
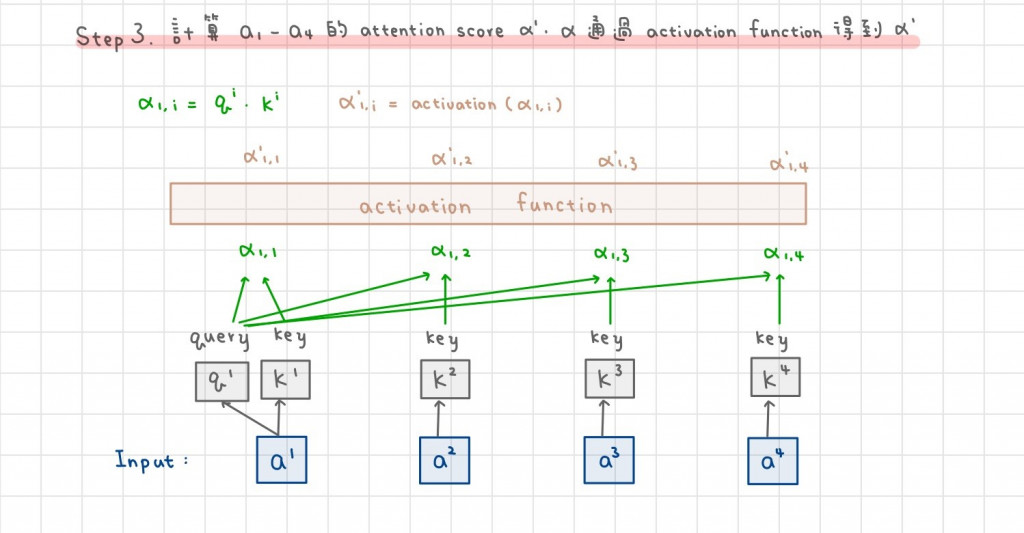
Attention scores α' 代表每個元素(a1-a4)和 a1 的相似程度,計算方式是將每個元素的 key k1-k4 和 a1 query 內積得到 α,再經過 activation function 後算出 α'。此處的 activation function 較常用的是 softmax,不過也可以用 ReLU。
和 a1 越相似的元素,其內積越大,α'也會越大。
將每個元素(a1-a4)再各自乘上 Wv,得到 value(v1-v4),並利用 α' 計算加權總和,得到 b。
換句話說,和 a1 越相似的元素,其 v 的權重 α' 較大,對 b 的影響也較多。

對每個元素(a1-a4)重複以上四個步驟,可以得到各自的輸出(b1-b4)。並且 self-attention 在計算時是平行輸入,意即同時輸入一個序列 [a1, a2, a3, a4],可以同時輸出 [b1, b2, b3, b4]。
將以上步驟寫成矩陣形式,如下圖表示;

其中唯一需要學習的矩陣是 Wq、Wk 和 Wv,是從訓練資料中找出來的。
以上為 self-attention 的原理介紹。明天會介紹 Uber 如何使用這套技術,估算外送和司機的抵達時間,那我們明天再見吧!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:


 iThome鐵人賽
iThome鐵人賽